AI Architecture
Secure AI agent integration: the 4-layer architecture I build
Autonomous AI agents need access to your live business data — without leaking PII, hallucinating financial promises, or burning thousands in tokens. Here is the middleware architecture I build to make that safe.
On this page
If you run a business, an agency, or a technical team, you have probably realised the bottleneck to using AI is not the AI itself — it is the infrastructure.
You do not need another generic chatbot. You need autonomous AI agents that can read your private databases, qualify leads, draft quotes, and update your CRM. But handing a large language model the keys to your live production data is a serious security risk.
That is where the Agent Architectcomes in. Below is exactly how I design, build, and deploy secure backend pipelines that connect legacy business systems to modern AI agents — whether you are a boutique law firm automating client intake or a startup bleeding cloud spend on inefficient agent code.
From chatbots to autonomous agents
Before the architecture, the distinction that matters: a traditional chatbot versus an AI agent.
The value of AI has moved off the chat interface and into the backend data pipeline.
Who is the prime match for custom AI architecture?
These services are not for businesses chasing a $50 ChatGPT wrapper. I partner with established organisations that already have data, workflows, and real security requirements.
| Industry | The pain point | The AI-agent solution | Legacy systems |
|---|---|---|---|
| Real estate & agencies | Web leads go cold overnight while a human is asleep. | Instant, context-aware lead qualification over SMS or email. | HubSpot, Salesforce, WordPress |
| Boutique legal / accounting | Hours lost reviewing unstructured PDFs for client intake. | A vector pipeline that extracts facts and drafts briefs. | Clio, QuickBooks, secure FTP |
| Local service (HVAC / roofing) | Estimators spend 40% of the day on basic quotes. | An agent checks inventory APIs and drafts quotes for approval. | ServiceTitan, Jobber, custom SQL |
| Tech-debt startups | Unoptimised agent queries make cloud bills explode. | Database indexing, caching layers, pipeline optimisation. | Postgres, Firebase, AWS S3 |
If your business moves data between a CRM, an inbox, and a database, you are leaving hundreds of hours on the table without a secure agentic pipeline.
Why you can’t just “plug in” AI
The biggest mistake companies make is wiring a legacy database straight to an LLM provider. That opens three critical vulnerabilities — toggle between the naive and secured wiring to see how each one is handled:
Secured middleware
PII leakage
A regex/redaction layer scrubs PII before any text reaches the model, so the LLM never sees the raw record.
Costly hallucinations
Answers are grounded in retrieved company data, and a human approval step gates anything that touches money or records.
Token burn & infinite loops
Rate limiting, request queues, and observability cap volume and surface runaway reasoning loops before they cost you.
The fix is not to build the AI. It is to build the security middleware around it.
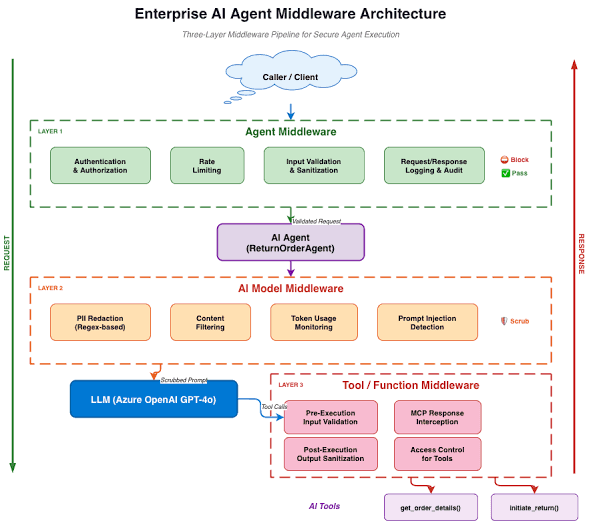
How I handle it: the 4-layer integration architecture
My primary deliverable is a robust, secure backend pipeline — a wall between your sensitive data and the model. Open each layer:
Workflow
When a new lead fills out a form or an invoice lands in Google Drive, a webhook fires — no manual input required.
Tech stack
Firestore triggers, serverless Vercel functions, or self-hosted automation like n8n, depending on your infrastructure.
Visualizing the data flow
Here is how a request actually moves through the system.
Prefer to watch it? Here is a short walkthrough of the same pipeline.
Things to consider before we build
Putting AI into your backend is real engineering. Before we partner, a few technical realities to plan for:
- Latency is unavoidable.Standard APIs answer in milliseconds; multi-step agents using chain-of-thought reasoning can take 5–15 seconds. We design UI states — loading skeletons, async email notifications — that manage expectations during that window.
- Rate limits are strict. Salesforce and Shopify cap request rates. Sync 5,000 records at once and your account gets throttled. The architecture includes queuing (Redis) to keep the agent inside safe limits.
- Data cleanliness dictates quality. Garbage in, garbage out: duplicate contacts and stale PDFs make the vector database return contradictions. We may schedule a data-cleaning phase first.
- No vendor lock-in.I do not hardcode you to one provider. The middleware is model-agnostic — when a better or cheaper model ships, we swap an environment variable and the pipeline upgrades.
Deliverables: what you actually get
You are not getting a slide deck. You receive a working, production-ready infrastructure ecosystem:
- Production source code. A private GitHub repo with the Node.js / Express middleware, commented and documented.
- Deployed infrastructure. Live hosting (typically Vercel or AWS) with custom domains and SSL.
- CI/CD pipeline. GitHub Actions that test and deploy logic changes with zero downtime.
- Vector database setup. A configured, indexed vector store (Pinecone / pgvector) seeded with your first batch of company knowledge.
- Comprehensive documentation. A handover covering key rotation, webhook routing, and how to read the logs.
Pricing preferences & packages
I work on a value-based, flat-fee model. Hourly billing penalises efficiency and misaligns incentives — you are paying for the architectural certainty that your data is safe and the pipeline works.
| Phase | What it covers | Typical investment |
|---|---|---|
| Phase 1 — Architecture & setup | Custom middleware, webhook routing, PII-scrubbing logic, and API-hub integration. | $1,500 – $3,000 (flat) |
| Phase 2 — Vector memory (optional) | Ingesting unstructured legacy data (PDFs, old emails) and configuring the RAG pipeline. | $800 – $1,200 (flat) |
| Phase 3 — Managed maintenance | Uptime monitoring, hosting, API-key rotation, and monthly log audits. | $200 / month (retainer) |
What to expect: timeline & workflow
Transparency is the foundation of the process. A typical engagement runs like this:
- Discovery (days 1–2). We map the exact workflow to automate, identify the legacy databases, and document the API endpoints we need.
- Architecture & scaffolding (days 3–7). I build the repo, set up CI/CD, and configure the authentication hubs.
- Middleware & logic (days 8–14). The heavy lifting: webhook listeners, sanitisation scripts, and failsafe logic.
- Testing & calibration (days 15–18). We push dummy data through, try to break the agent, and verify the human-in-the-loop alerts fire every time.
- Go-live & handover (day 21). The system flips to production; you get the documentation and a recorded walkthrough of the codebase.
Ready to build your digital fortress?
AI agents are the most powerful operational leverage available to a business today — but they are only as good as the infrastructure under them. Stop settling for fragile Zapier chains and risky direct-to-LLM wiring, and build a secure, scalable pipeline instead.